When I started working as a Data Scientist nearly ten years ago, the data science team I joined did something I found really strange at first: They had a single GitHub repo where they put all their “throwaway” code. An R script to produce some plots for a presentation, a Python notebook with a machine learning proof-of-concept, a bash script for cleaning some logs. It all went into the same repo. Initially, this felt sloppy to me, and sure, there are better ways to organize code, but I’ve come to learn that not having a single place for throwaway code in a team is far worse. Without a place for throwaway code, what’s going to happen is:
- Some ambitious person on the team will create a new GitHub repo for every single analysis/POC/thing they do, “swamping” the GitHub namespace.
- Some others will stow their code on the company wiki or drop it in the team Slack channel.
- But most people aren’t going to put it anywhere, and we all know that code “available on request” often isn’t available at all.
So, in all teams I’ve worked in, I’ve set up a GitHub repo that looks something like this:
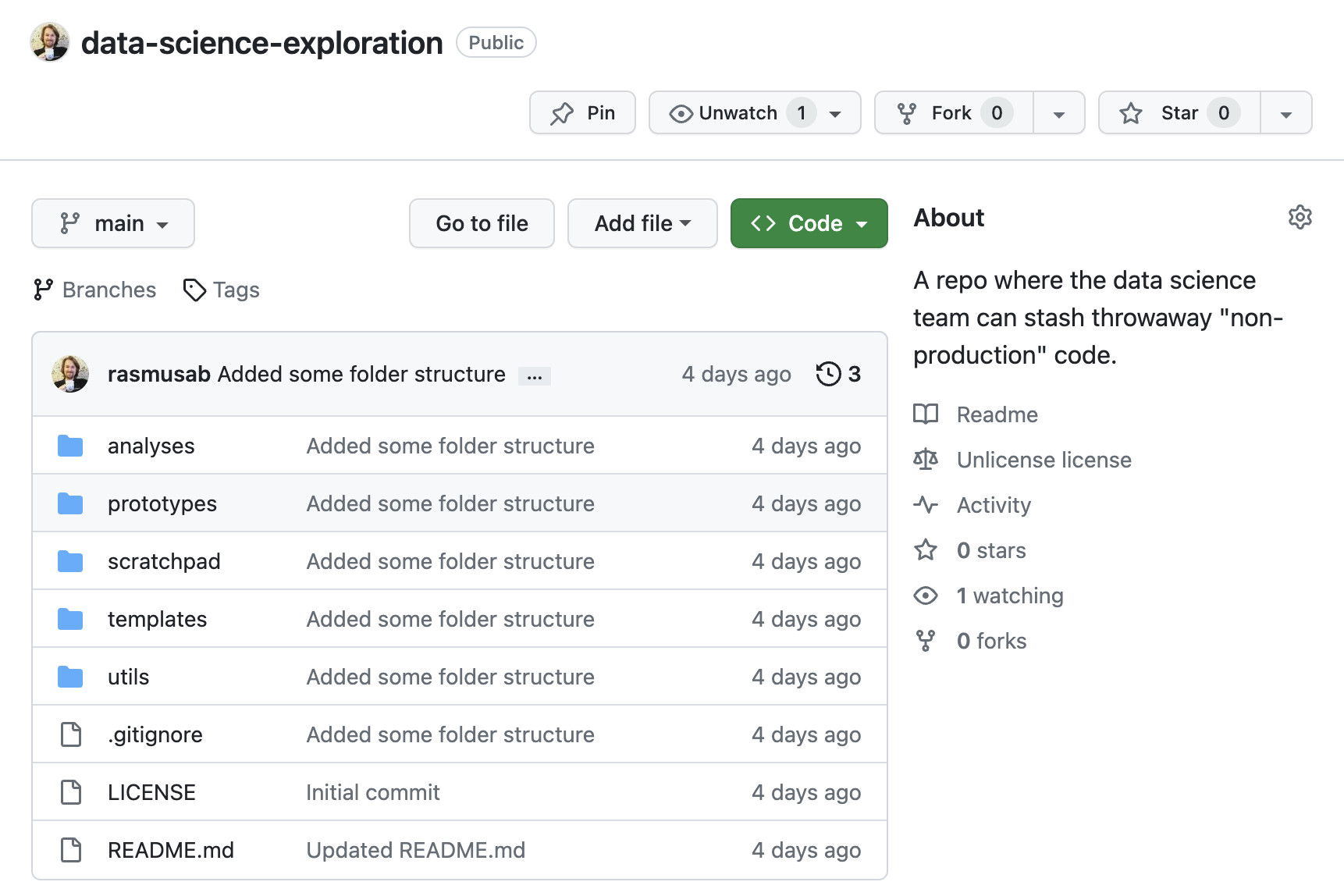
With the following blurb: A place for non-production scripts, notebooks, and other throwaway code. Don’t bother with branches and pull requests, unless you want a review, as this is more of a Dropbox folder masquerading as a GitHub repo. If you want to set up a similar repo, feel free to take a look at
the ds-exploration-template repo over here.
And having such a repo has been very useful! It’s not the best place to put code, it does tend to become a bit disorganized after a while, but it is a place to put code, and where it’s easy to do so. And then, when you get a request that makes you think “Ah! I remember that Kristin (who’s on parental leave and shouldn’t be bothered) did something similar last year!” it’s really great to be able to go to that repo and find that code.